libhdf4-dev is required for pyhdf to read .hdf4 files.
sudo apt install -y libhdf4-dev
pip install banet
Dataset
The dataset used to train the model and the pretrained weights are available at https://drive.google.com/drive/folders/1142CCdtyekXHc60gtIgmIYzHdv8lMHqN?usp=sharing. Notice that the size of the full dataset is about 160 GB. You can, however, donwload individual regions in case you want to test with a smaller dataset.
Generate predictions for a new region in 5 steps
The procedure to generate predictions for a new region or for a different period of the existing regions is straightforward.
Step 1. Define a
.jsonfile with region name, bounding boxes and spatial resolution. Region definition files are by default ondata/regionsand should be named asR_{name}.json, where name is the name you give to the region inside the file. For example for Iberian Peninsula region the filedata/regions/R_PI.jsoncontains the following:{"name": "PI", "bbox": [-10, 36, 5, 44], "pixel_size": 0.01}.Step 2. To download the reflectance data the command line script
banet_viirs750_downloadcan be used. However, in order to use it, you need to first register at the website (https://ladsweb.modaps.eosdis.nasa.gov/) and generate an authentication token.Step 3. Next you need to download the VIIRS active fire data for the region you seletected. This procedure is manual but you should be able to request data for the entire temporal window in one go. To do that go to https://firms.modaps.eosdis.nasa.gov/download/, select
Create New Request, select the region based on your region bounding box, for fire data source selectVIIRS, then select the date range and finally.csvfor the file format. You should receive an email with the confirmation and later another with the link to download the data. If not go back to the download page enter the email you used for the request and chooseCheck Request Status. If it is completed the download link will appear. Once you have the file place it indata/hotspotsand name ithotspots{name}.csvwhere name is the name of the region as in the.jsonfile defined in Step 1.Step 4. Now that you have all the data, you can use the command line script
banet_create_dataset.Step 5. Finally you can use the
banet_predict_monthlycommand line script to generate the model outputs.
Note: Some examples of usage for the command line tools are available in the documentation.
Train the model from scratch
To train the model you need a dataset of image tiles and the respective targets. The data for the 5 study regions is available for download at https://drive.google.com/drive/folders/1142CCdtyekXHc60gtIgmIYzHdv8lMHqN?usp=sharing. In case you want to train a model on different regions the procedure to collect VIIRS data is described on Generate predictions for a new region in 5 steps above.
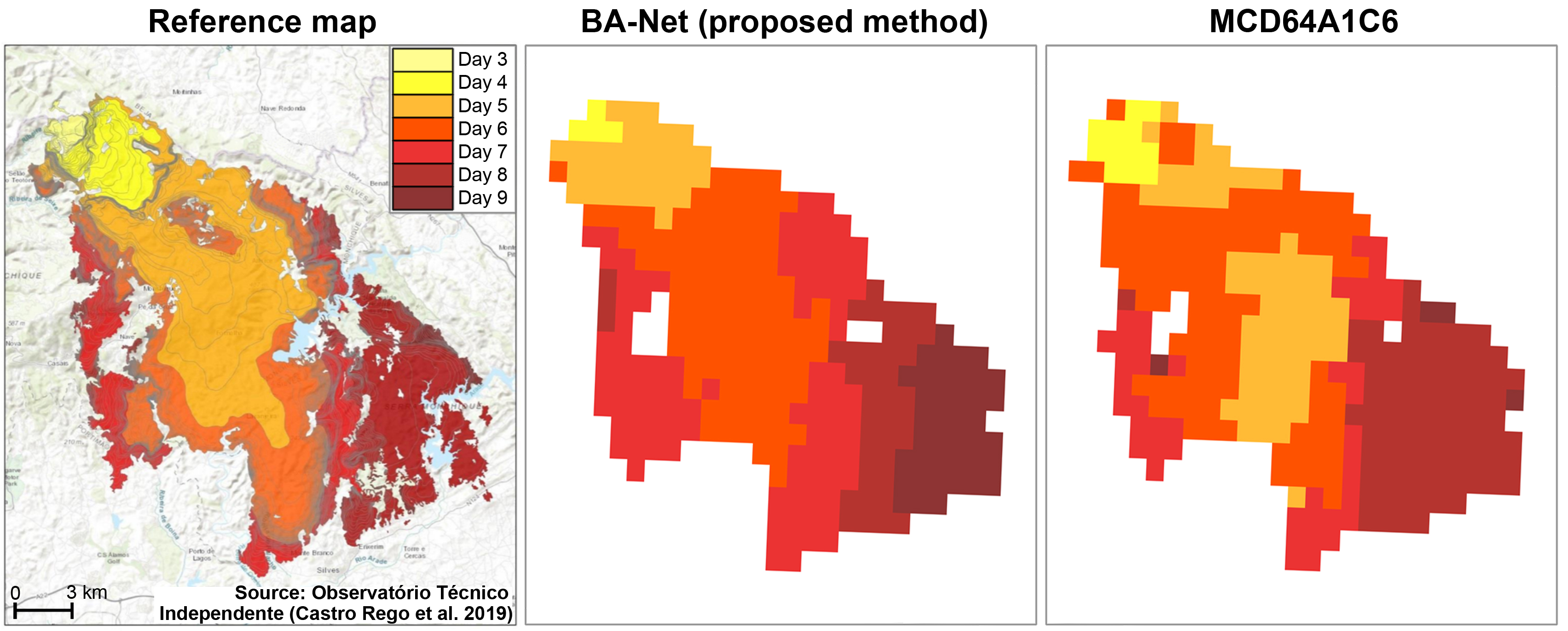
Step 1. In case you opted for new regions you need to collect MCD64A1 collection 6 burned areas to use as targets. MCD64A1 collection 6 data can be downloaded from
ftp://ba1.geog.umd.edu/server (description and credentials available on http://modis-fire.umd.edu/files/MODIS_C6_BA_User_Guide_1.2.pdf section 4). Once you log into the server go toCollection 6/TIFFfolder and download data for the window or windows covering your region (Figure 2 on the user guide shows the delineation of the windows).Step 2. Once you have the data you can generate a dataset with
banet_create_datasetandbanet_dataset2tilescommand line tools. If you downloaded the dataset already in.matfiles format provided in the url above then you just use thebanet_dataset2tiles.Step 3. To train the model the
banet_train_modelcommand line tool is provided. To use sequences of 64 days with 128x128 size tiles and batch size of 1, you need a 8 GB GPU. You can try reducing the sequence length if your GPU has less memory or increase the batch size otherwise.
Note: Some examples of usage for the command line tools are available in the documentation.
Fine-tune the model for a specific region or for other data source (transfer learning)
It is possible to fine-tune the trained model weights to a specific region or using a different source for the input data (e.g., data from VIIRS 375m bands or data from another satellite). The easiest way to include a new dataset is to write a Dataset class similar to Viirs750Dataset or the other dataset classes on banet.data. Once you have the new dataset you can follow the Train the model from scratch guideline and the only change you need to make is to make sure you load the pretrained weights before starting to train.
Citation
@article{pinto2020banet,
title={A deep learning approach for mapping and dating burned areas using temporal sequences of satellite images},
author={Pinto, Miguel M and Libonati, Renata and Trigo, Ricardo M and Trigo, Isabel F and DaCamara, Carlos C},
journal={ISPRS Journal of Photogrammetry and Remote Sensing},
volume={160},
pages={260--274},
year={2020},
publisher={Elsevier}
}